In this post, we are going to look at job that moves data from DB2, a transactional system, to Hadoop. This data copy or OI serves as the bedrock for a slew of analytics within and beyond the Hadoop data platform, supporting not only datawarehousing tasks but also (possibly) business intelligence in the rare cases where access to raw data is necessary to answer business questions.
So here's a piece of the job:
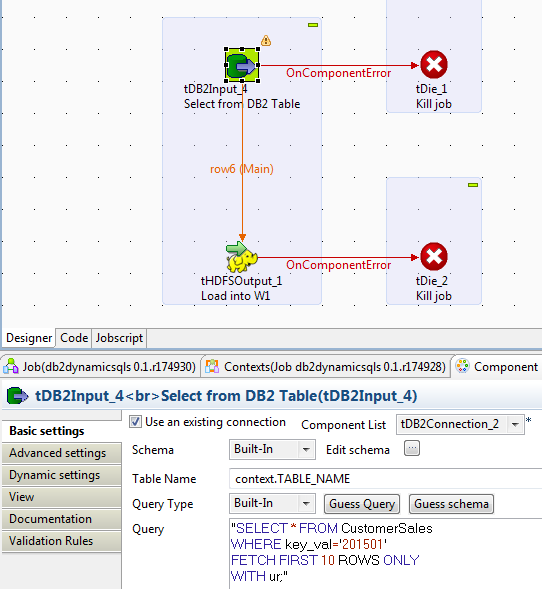
As shown above, the query is specified and a schema is also defined that matches the set of fields in the table CustomerSales. (Note: It's not good practice to use 'select * from table' in data integration jobs - if columns shift, the job will die).
So this design works well. The problem however, is that when we have say 100 tables to load from the source to the target, we have to repeat this process with unique queries for each table, and corresponding schemas for each table. Our job could end up being very large - to accomodate the number of tables, or we could end up with lots of jobs, one for each table or a set of tables. While these all work, there's a better way to do this.
A well documented feature in Talend is Dynamic Schema. Dynamic schema feature allows us to skip specifying the schema for each query, and simply letting Talend 'discover' the schema based on the query or table name. Combining this feature with Select SQL statements allows us to implement a pattern where a set of Select SQL statements are run again using one or two simple Talend jobs.
To convert this simple job into a reusable pattern, we redesign the job to read or generate a set of Select SQL statements for each table in the source, in this case DB2. We loop through the list of Select statements and execute them using the DB2Input component. Because we don't know the schema for each Select statement, we change the type of just one column in the Schema window to Dynamic.
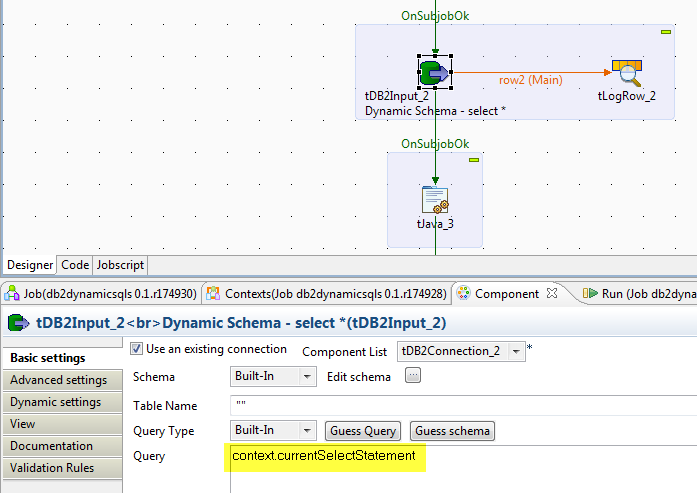
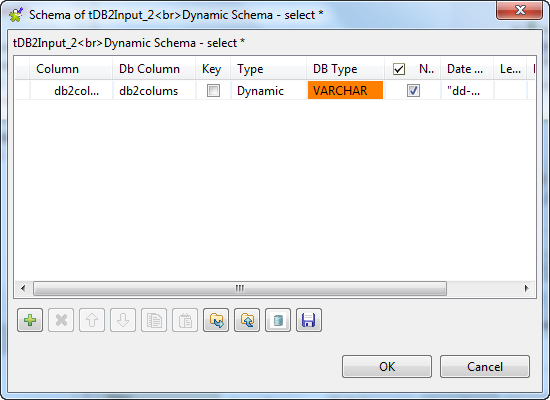
When the query is run, it will determine the schema based on the Select statement.

When a different Select statement is used that retrieves only a few columns...
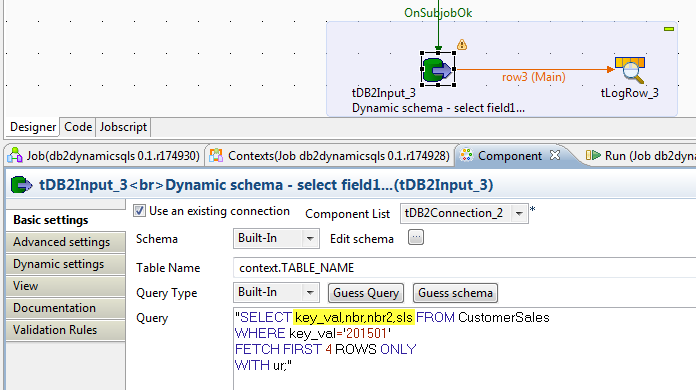
it works as expected.
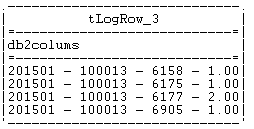
While this design works for reading and printing to console using tLogRow as shown here, it fails when writing/streaming the data to HDFS (Hadoop file system) because the component tHDFSOutput does not support dynamic schema functionality. It needs to be passed a data flow that includes the schema of the data to write to Hadoop.
One standard way to deal with components that don't support dynamic schema functionality is to use the tSetDynamicSchema component. In this particular case, an easier and more efficient method of both moving the data to Hadoop AND handling the lack of support for dynamic schema is to change from using a tHDFSOutput (which streams to Hadoop) to a tHDFSPut, which moves the file from local to HDFS in one fell swoop. Because we don't write the column or header list at the start of the file, the output file that's placed in HDFS is compliant and queriable (through Hive etc...).
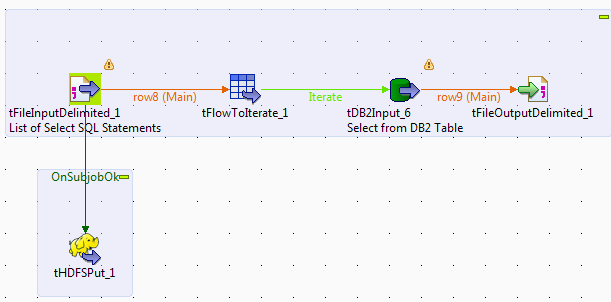
This pattern can be repeated for dozens of tables to load them into Hadoop with the minimum number of jobs and the least complexity.
