In a Hadoop 2.x High Availablity cluster, because there are multiple HiveServers, we can no longer hard-code our connection to any HiveServer because at some point, one of them could be unavailable or in passive mode. Multiple HiveServers work in an active/passive fashion. In order to always connect to the active host, we rely on the Zookeeper service running on multiple Zookeeper servers. These servers will keep track of the available HiveServers across the cluster and direct calls to the active HiveServer. Therefore in a HA environment, we now need to connect using the Zookeeper connection string instead. This connecting string is configured and stored in the yarn-site.xml file (in the hadoop.registry.zk.quorum property).
Ultimately, when configured properly, a Talend job should generate a JDBC URL that looks like the following in order to connect to Hadoop in HA:
jdbc:hive2://<zookeeperServer1>:port,<zookeeperServer2>:port,<zookeeperServer3>:port/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
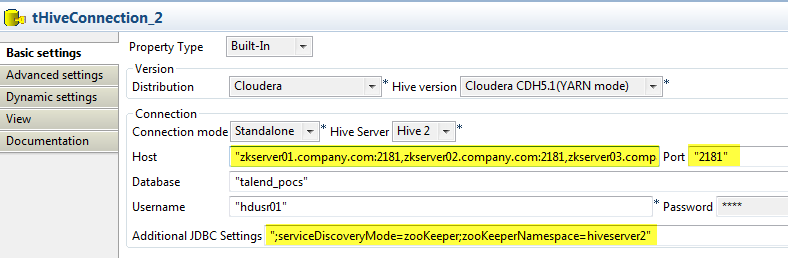
To do that, in place of specifiying the Hive Host in the Host text box (see below), we specify the Zookeeper quorum. Note that we leave out the trailing Zookeeper port because the Talend generated code appends the port from the Port field. To clarify, here's the text that's entered in the Host field below:
"zkserver01.company.com:2181,zkserver02.company.com:2181,zkserver03.company.com"
Then the Additional JDBC URL is populated with: ";serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2"
Having tested this and confirmed that it's working, the best practice would be to create a metadata connection using these settings for the various lifecycles.
